
Opinionated Mental Models for Agentic Workflows
Tool-agnostic mental models for the agentic era. What to delegate, how to design feedback loops, and why human judgement scales LLM output.
Two years ago, precisely before Christmas Day, I wrote about using LLM for software development to leverage our shipping speed and capabilities. Fast forward, January 2026, now it’s time for reflection (and crazier writing hopefully) especially about what I wrote about AI-assisted software development that completely changed. Some of them including my opinion, method, and tools are pretty irrelevant today. My opinion about how we integrate into our current “engineering” workflow also changed a lot. The model capabilities and current AI tools available right now also changed a lot for LESS THAN A YEAR.
As stated in my previous blog, I had been using cursor as my go-to IDE for AI-assisted programming last year. I also mentioned bolt, lovable, and v0 for prototyping web UI too. This year, I have completely changed how I write code and use AI compared to last year (oops, less than a year actually). Most of my workflows are now in terminal, even writing code itself (neovim btw).
I feel like what I wrote in my blog about previous years has aged like milk and some of them feel very wrong currently especially AI-powered development and sigh.. about crypto ai agents. I wrote about specific tools, specific prompts, and specific workflows or methods, some of them are outdated (I won’t mention any, you may know it).
These agentic workflows, vibe coding, AI-assisted engineering, context engineering or whatever it is called still feels early to me in terms of real real serious maturity despite people starting to catch up to the capabilities of current SOTA models. While some argue that it is completely bullshit. Some companies and the enterprises started to adapt to the current AI paradigm, giving their employees subscriptions to AI tools such as cursor, claude code, and not the worthy one which is copilot. Some people glaze too much about the latest models and tools capabilities (honorable mentions, opus 4.5 with claude code harness).
Based on my personal observation, with current state of AI-powered coding and workflows, we can separate types of individuals who use AI as:
- Overhype Crowds, basically overglazing and hyping too much every time there is a latest model release like “this is AGI, it’s over, billions of programmers will be replaced in less than a year”. Indeed they acknowledge the capabilities of AI but it’s kind of hyperbole that at the end it will result in fearmongering to the masses and overstate something that could be huge misinformation at the end.
- Shiny new things, try every newest tool and model available, very chronically online about latest AI capabilities. Keep switching tools over time in short periods. This is probably somehow myself unironically as I changed tools a few times from cursor -> claude code -> codex -> back to claude code + opencode. This type of person can be divided again as FOMO, braindead following shiny new things or use it to follow current LLM capabilities, stay true to themselves and able to filter what’s actually useful (higher signal, less noise).
- People who are only able to use specific tools due to company strictness. I have seen people (and my friends) that are only able to use copilot or internal tools due to other AI tools not being allowed to be used, even blocked by company internal network. Regarding AI frontier labs, I don’t know if direct big competitors—OpenAI,
Meta, Anthropic, and Google DeepMind—are limited to use their own tools for work or allowed to use their competitor’s tools for their work or not but I assume that they are only allowed to use their internal tools and their own models for work. - Denial stage, people in denial about current LLM capabilities, what current SOTA models are able to accomplish within less than a year, even anti-AI. Not really open about what’s going on. Some people may still think that current LLMs generate absolute bad code most of the time and hallucinate a lot. Not able to generate high quality production code. Not embracing what’s really going on.
- Don’t know what is really going on.. at all. Worse than denial stage. Maybe all they know is hey you wasted three gallons of water for generating these prediction tokens. Don’t know what LLMs have accomplished, their capabilities, etc. Clueless about how to use LLM other than asking LLM for helping with their simple assignments whether it’s for school tasks or daily life ones.
- Leveraging LLM to the max. Built their own workflow and system to enhance LLM capabilities as much as possible. This type of people can be divided again because I have seen it not only for coding and programming wise but also creative works (I’m not talking about endless AI slop videos generator one) and other domain works (ex: SEO, marketing/gtm, finance, biz, etc.).
What I mean by “leveraging LLM to the max” here is the ability to understand what an LLM is, its strengths and weaknesses, then able to pull out LLM strength and its possibility as much as possible out of current models while trying to reduce its weakness. We know that LLM has limited context length thus there is a term we call today as context engineering, the ability to create and manage context to get the best model output. This includes prompt, instructions, documents, external data, tool calls, and memory/history 1. It is hard to articulate this type clearly but to make it clear, I describe this kind of person as they know what they are doing.
Back to the topic, fast forward the tools are moving fast while the frontier labs keep competing each other to release their best models as fast as possible with its unnecessary benchmarkmaxxing. Claude code today maybe won’t be the same claude code in a year. Imagine opus 5, gemini pro 4, and gpt-6. Codex, kilocode, cursor, whatever comes next, I believe that the interface, how we interact (ux & dx) will change, the capabilities will expand.
This writing will be dedicated to what I think that hopefully won’t change, completely tool-agnostic, the underlying mental models and the thinking process to interact with the future machine god.
- what to delegate, what not to delegate
- human feedback loops design
- context structure
- when you intervene vs let it run
—dangerously-skip-permissions
- Human judgement scales LLM output — the more domain expertise and taste you have, the better code the model produces
- Delegation is a skill — knowing what to delegate, how much context to transfer, and when to take back control
- Feedback loops as infrastructure — design tight, automated verification cycles (ex: ralph loop pattern) so the agent self-corrects
- Verification > Trust — type systems, tests, linters are your safety net; never trust agent output blindly
- Declarative systems win — reproducible, sandboxed environments (like nix) are ideal agentic playgrounds
2025 Wrapped, Enter the TUI-morphism
Let’s do some quick recap of 2025, what has been happening in my own perspective about AI-assisted coding & programming.
All started from when claude code was released, around February 2025. Instead of building AI-powered IDE or IDE extension, The Anthropic team were approaching differently for their own new product, not GUI app but TUI-based app. You write claude in your terminal and it’s ready to assist whatever you need through terminal workflow. It can interact directly with your terminal environment such as unix commands (ls, ll, cd, mkdir, grep, etc). Maybe it sounds quite similar to aider but actually different as both tools have different approaches for users/developers experience for their tools.
Then there were a bunch of TUI-based AI tools that spawned. OpenAI made codex, another agentic coding tool similar to claude code but it’s written in rust so must be blazingly fast and open-source unlike claude code. Google and Alibaba made their own coding tools too, gemini-cli and qwen-code.
While those frontier labs made their opinionated coding tool to serve their own model, there is also open-source agentic tool similar to what claude code is but you can switch freely to use other models as well easily. Software company that made sst, Anomaly, developed their own open-source agentic tool called opencode this year (around May-June) so users are able to use and switch all models available including using existing claude plan, using openrouter, and specific model providers as inferences while they’re also able to customize and configure their tool for their own workflow. Even better, as it is open-source project, we can contribute and open PR directly to the repo. Charmbracelet, the “pretty CLI & TUI” software company, also made their own agentic coding tool similar to opencode. Both company and their open-source tool use their own TUI framework. Charm used their existing bubbly cutesy glamorous concept TUI-framework based on golang, bubble tea while Anomaly developed their own TUI framework this year which is opentui this year written with mix of typescript and zig.
CLI.. Why???
Maybe some of you even wonder, why most of the tools are available as CLI or TUI-based instead of high ram usage electron GUI-based apps. I saw that some people even migrating back to cursor/vscode rather than using cli-based apps like claude code. Personally, I love cli-based more so I can larp as performative hacker looking guy when I was working in an office or cafe because of flexibility, customization, and control I have rather than standalone well-designed apps. I can feel the touch between me and the computer more closely as it reduces abstraction layer disguised as “user-friendliness” when I want to interact with my computer. CLI-based app also (supposed to be) uses less resources, way lower than most of desktop and browser apps especially electron-wrapper or chrome-fork.
As CLI-based coding agents are editor-agnostic, you can plug-in whatever IDE or text editor you are using. You can open claude code on cursor, vscode, or zed as it can be spawned directly by typing “claude” on terminal. You can also split it as vertical or horizontal panel on your favorite panel, one is opening claude code, the other panel is opening vim or emacs.
It feels nice that LLM can interact with our terminal directly using their tool calling to our UNIX system directly such as grep and ls. Especially if our project directory has a bunch of dependencies installed like uv and bun, LLMs can interact and test directly whenever need confirmation, or do some git operations..
The most obvious advantage of those coding agents being CLI-based rather than desktop app are the ability to customize further beyond your computer. You can spin up new VM, install claude code in there, and customize further your development environment in your own VM. Then you can setup your own network/internal VPN like tailscale to connect between your own device (mac and iphone for example) to your VM. Recently, I often SSH to my own VM to spin-up claude code and opencode as background worker that i can leave the task for coding. With app being terminal-based, not only we use lower resource but we eliminate more interactivity abstraction layer for more flexibility like this. You can also setup tmux or screen as multiplexer to make your own async workflow and enhance further with tiling window manager to adjust between your terminal with other apps especially for workspaces switching and window splitting (on macOS I’m using aerospace while on my desktop, I’m using hyprland).
Changed The Way I Work
With these new agentic coding tools, I have changed the way I’m doing programming and writing code by myself. Quick lore recap, previously as biomedical engineering undergraduate, I used vscode as default IDE most of the time and jupyter notebook to write and test code that related to data & ML. Then in 2024, I changed my go-to editor from vscode to cursor as I’m addicted to cursor tab (the best tab completion engine I’ve ever used so far) and having better user experience to interact with LLM than copilot from vscode.
I have explored a lot of new tools whether it’s existing tools or tools that released this year. Example of tools and something that I’ve discovered and used in 2025 that I would classify as game-changing personally: tailscale, nix, tmux, and agentic tools I mentioned above (obviously).
Now, in 2026, I comfortably write most of the code with neovim. I also write my blog on neovim as text editor with localhost server of astro website shown in my brave browser, splitted by my own aerospace that configured with my nix dotfiles on top of git worktree that separated between main branch worktree, feature implementation worktree, and writing draft worktree. I thought that learning vim keymaps and configuring your own neovim for coding are productive slop to justify your coding skill and performance but turned out I was wrong. I found it really useful and makes my programming faster including for debugging, analyzing codebase, searching specific file & code, and writing code. Using neovim also makes my work related to ssh-ing to server easier as I can just write using vim on server directly rather than nano which I found annoying in the first place to be with. Well, I don’t memorize all of vim keymaps, mostly what I use most are simple keymaps such as :wq, !wq, :ggVG, :/, :g, and :<line-number> (well actually way more than that).
Somehow Nix is Perfect DevOps Tool to Vibe with
This one is seriously personal perspective, I don’t really care if you disagree with me but I found that nix is a perfect programming language to vibecode with related to manage packages, build, and devops. Nature of nix being purely functional and declarative feels perfect for prototyping, vibecoding, and agentic development. I have been exploring what nix and opus are capable of and it was a really amazing experience. Not only you write code for your own development environment as declarative configuration but also the multiple ways to configure your agent environment. You can use nix for sandbox-ing your claude, codex, or opencode with multiple design patterns while sticking to nix core philosophy.
As of today, I have been experimenting with making customized nixos machine with clan framework to build dedicated VM to let agent run wild within sandbox, with nix as one of main code infrastructure here.
 geoff@GeoffreyHuntley
geoff@GeoffreyHuntley
I also wrote a blog about learning nix you can read here.
My Current Setup
As I changed the way I work, most of the CLI tools especially agentic tools are moved to my own personal VM (derived from my baremetal server) as work station that you can see on my about page. I have been thinking of building and setting up my own dev vm so I can customize my dev environment to the max and there is clear separation between my own mac with actual code plumbing and testing environment. A tweet from @elliotarledge about having separate rig as work station really articulates well what I have been thinking of here:
 Elliot Arledge@elliotarledge
Elliot Arledge@elliotarledgeAs the models and these agentic tools become too good now, I’m also planning to make my own dev vm to be more agent-friendly so claude is able to do some sysadmin work, committing and making some PR, opening issues, doing work in background, etc. I’m experimenting with all the capabilities to fully-maximize “agent” as worker machine similar to mining machine in factorio for task delegation that might be connected with cable-like node or network for my soon-to-be-automated workflow. As someone who has played factorio and done some redstone-engineering on minecraft, you know that the end game is to automate your work as much as possible, maximize your efficiency.
The Foundational Shift
Let’s play a game of assumption, we want to take away the joy of writing code manually and we want to focus on building part and automate coding as much as possible. Coding is fully-delegated to agentic tool, we may call it as “X”
Now as we assume that writing code is fully-automated and delegated to AI, how do we know we achieve what we want? We verify the output of code written by AI and the result of it.
Does it compile?
Is this the output what we want to achieve?
Is the process from start to end right?
Does it return any bugs or errors? If yes, why is it? What’s the root cause?
Yes we are not writing code anymore but we still need to know WHAT IS GOING ON and VERIFY THE OUTPUT. If possible, the entire process and its written code. We eliminate coding yet we have to understand the code itself. Understanding code means we should be able to read the code itself. Therefore, having the ability to read, understand, and differentiate the quality of code written by the model is important.
I call it as human judgement, the ability to judge code written by the model. The more experienced (senior-level) and the better you write code as an engineer, we can assume that the better your human judgement skills are. You know what’s going on and able to navigate quickly what went wrong on the code. As a consequence, we made a paradox. The better you write the code, the better your code reading ability too.
So, is there
symlinkcorrelation between code writing skill and code reading skill?
Before I try to answer that simple question. I want to add disclaimer that I’m bad at writing code, and probably still am to this day as I’m still learning how to write proper good code, best implementation, and still not able to solve all easy leetcode challenges. But the more I learn and catch up with what I don’t know about programming, compute, networking, or whatever domain knowledge I need to know correctly, the better the code output written by the model. More knowledge of web development made my instructions, contexts, and prompts curated more clearly to the model. As a result, the code output is more clear and better than when I don’t really know what is really going on and can’t judge what’s the best way or approach in specific moment.
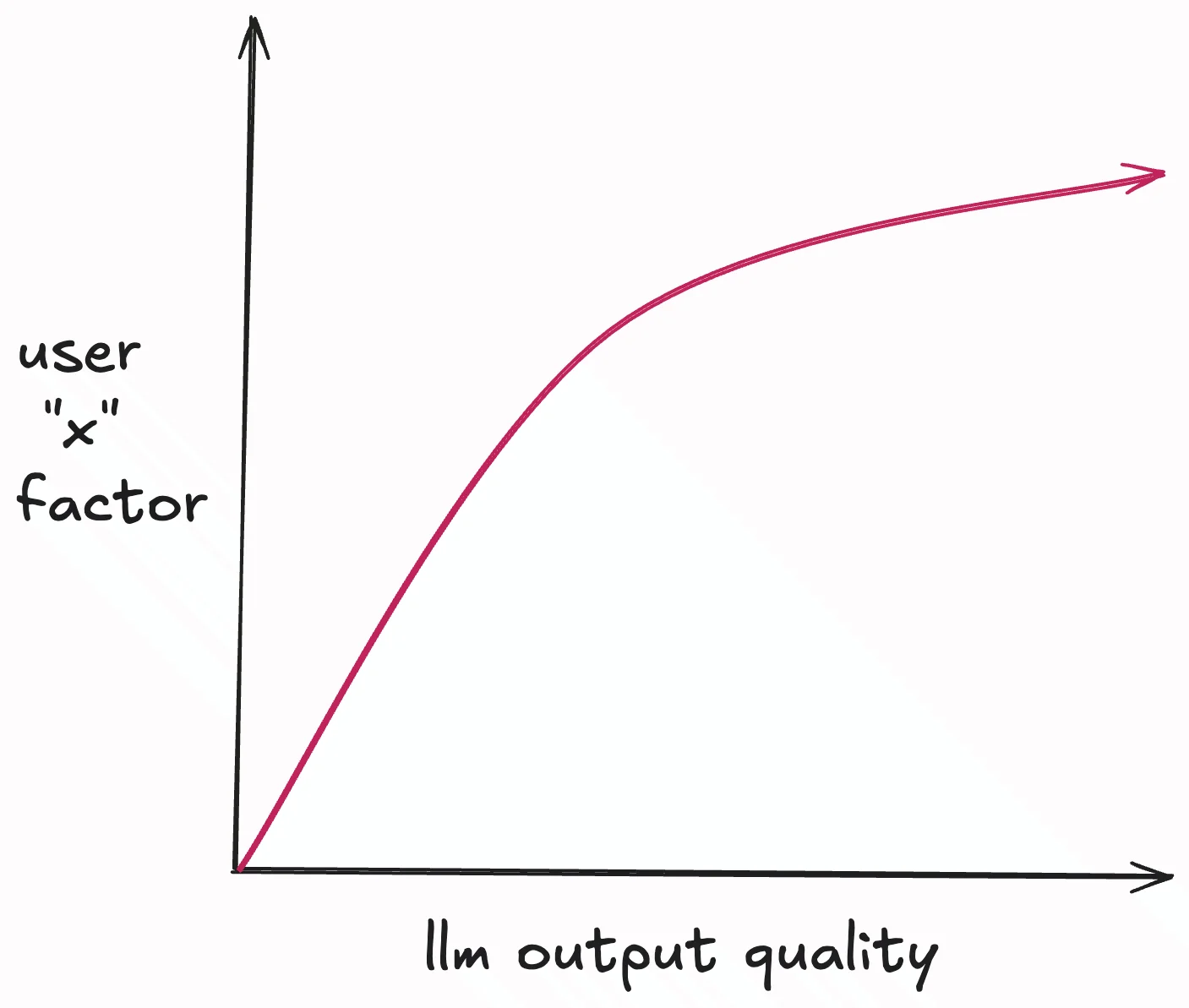
Here is fully-made up theoretical correlation graph between llm output and user “x” factor that I’m trying to model here. The “x” factor including the human (user) judgement, the human taste, the right contexts gathered by the user, user prompt, and the user domain expertise.
Hence, my answer is more domain expertise, better ability to design the system and architecture, the better your human judgement and your taste is -> the better the code written by the model (also at least able to read code and know what’s going on too). Maybe the model itself knows everything, but I believe that the model output is scaled based on the human intelligence, taste, and knowledge. The more intelligence and better domain expertise the human is, the better model output and align with the human itself. I believe that human judgement and taste really matter the most in the current situation and in the future (I don’t know until when). Okay, now we go back to the previous term that related to this which is once again, context engineering.
An important note: as future model capabilities and intelligence might be increasing hypergrowth, my stupid hypothetical graph between user “x” factor and llm output quality might be irrelevant in the future. Maybe in the future you can just prompt “pls make this app make no mistake” and it really does without making any mistakes at all, production-grade, scalable, very-secure, with highest quality codebase that you can imagine.
Delegation Skill
I believe that the skill to know what to delegate or what not to delegate might be the most important skill here. Delegation isn’t about make AI do stuff only. It’s more about the balancing as:
- Under-specified delegation → garbage output, wasted cycles
- Over-specified delegation → you might as well have done it yourself
- Wrong-task delegation → some things aren’t delegatable (yet)
Delegation derived from context engineering, know what to handoff and how much context we can transfer to an LLM. Last, know when to take control. Delegation here also means that you do not delegate your thinking into ai, you delegate the task, share relevant knowledge & context, and instruction.
The Mental Models
The Sci-Fi Lens

If you were watching Ironman (or any marvel movies that has Tony Stark in it) or recent Superman movie character, Mr. Terrific, you may be familiar with Jarvis, the AI companion computer system of Tony Stark and T-Sphere, the agentic ai balls spherical electronic accessories used by Mr. Terrific.
Both are similar, used and viewed as tool by the superheroes I mentioned above while the tool shown in the movies are similar to LLM.
The t-spheres respond to Mr. Terrific’s mental and vocal commands. The spheres are then able to do what he is commanding such as self-propelled flight, creating holograms, manipulating other electronic devices, bombs, etc. Jarvis is giving information and what Tony Stark needs on demand based on his commands.
The keywords here are command which we can model it as an input to the tool itself whether through text, voice, or programmatic ways. We ask and instruct with natural language as a prompt to the model. The model then returns the output based on the input tokens. Current LLMs are also able to act by calling function and executing tool defined by the user or from the model itself.
To make it clearer, here is the idea as a pseudocode for tool-calling of Mr. Terrific’s t-sphere:
{
"name": "information_query",
"description": "Query databases and provide information (JARVIS-like)",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Information request"
},
"sources": {
"type": "array",
"items": {"type": "string"},
"description": "Databases to query: [internet, criminal_db, satellite, local_sensors]"
},
"urgency": {
"type": "string",
"enum": ["immediate", "thorough"],
"description": "Speed vs depth tradeoff"
}
},
"required": ["query"]
}
},
{
"name": "hack_system",
"description": "Infiltrate and manipulate electronic systems",
"parameters": {
"type": "object",
"properties": {
"target_system": {
"type": "string",
"description": "System to hack (door, camera, network, vehicle)"
},
"action": {
"type": "string",
"enum": ["bypass", "disable", "take_control", "extract_data", "inject_payload"],
"description": "Hacking action to perform"
},
"stealth_mode": {
"type": "boolean",
"description": "Whether to hide intrusion traces"
}
},
"required": ["target_system", "action"]
}
},Above, we defined tool definition for information_query and hack_system for t-sphere. Then we can inject these tools we defined in the system prompt of the t-sphere devices as long as the “language model” inside it supports tool-call. Once again this is purely fiction as we are trying to see what really LLM capable of in the eye of sci-fi and its endless potential capabilities in the future.
Why are we using Ironman and Mr. Terrific as example here?
Both have in common of using natural language as primary interface. Also use Jarvis and t-sphere as a tool instead of standalone powerful agent. The human, Tony Stark and Michael Holt make the decision then the tools either execute, assist, or inform based on the human instruction/command.
Current open-source SOTA LLMs such as GLM 4.7, MiniMax 2.1, and Kimi K2 can be run locally as long as you have big racks of compute to run it. Assume that in the future, open-source models will be much smaller in size, same performance or maybe a bit better than GLM 4.7 as an example, can be run with less than 48GB VRAM or maybe even on your phone while context windows are expanding and the voice interfaces to interact with LLMs are enhanced. There could be more wild things you can do and achieve. Even with current models, you can connect to your favorite agentic tools and vibecode with your phone using your server/desktop as the medium via termius and tailscale.
I believe that in the future, only a matter of time, there will be decent IoT-like hardware with LLM locally run inside and able to execute action through processing LLM response blended with function-calling programmed inside the device.
We are really close to having jarvis at home (bet it’s less than a decade). There is a prime example of my x oomfie that I found quite creative, he leveraged his domain expertise as devops and utilizing claude code opus as his 24/7 oncall engineer/sysadmin as his experiment. You can read his substack here.
The Gaming Lens

Previously, I mentioned factorio and redstone engineering in minecraft. This is my longer term mental model for computer-related work even pre-LLM era. Aim for
less work, focus on the output quality and quantities instead
Screw hustle culture, work 9-5, working late till night working like the way we did before, we should automate the boring part, repetitive part, or the part we don’t like as much as we can as we measure the result of the work, the output at the end of the day. Why would we want to work longer if the output is same quality as longer work? Time is more important currency than our work, we should prioritize our free time more than doing unnecessary work that doesn’t really matter. Focus on work that matters and the output itself then followed by the process of it to achieve the output. I wrote about automating yourself that influenced my thought here.
Why are we using factorio and minecraft (redstone engineering) as examples here?
Let’s say that the “coding” part in programming will be automated. Fully-generated by LLM with strong verification process. We can assume that our task will be more of managing the process of it like some factorio factory, also we design the automated software development system to make sure code generated by LLM itself is high quality coding output, the verification and its testing process should be strongly reliable to make sure its production-grade code, catch all the bugs before deployed to prod as much as possible especially crucial ones to serve the program/apps to end users properly.
 Sergey Karayev@sergeykarayev
Sergey Karayev@sergeykarayevIn factorio, first you land on the alien planet as a human. You mine all the resources you need with your hand using a pickaxe to build what you need such as mining drill, reactor, steam engine, etc. Then once you successfully built the foundational production power and resource-extracting machine, we started to build the circuit network and the transport to connect each factory building and machine to scale your factory. The basic concept of this probably can be viewed as you start writing small amounts of code or just vibecoded the basic function of it, then gradually scale it to make it even powerful, feature-rich, and able to serve more traffics.
Previously, we wrote code by our hand, manually, to make sure the code is good enough (high quality code) and reliable. Ensured that the code was well-tested and thoroughly debugged to minimize errors and ensure stability. Then we found several resources and tools to help us automate the process of writing code, baremetal server, GPU, LLM api, etc. Then we use the existing tools and resources available or maybe make our own to make software as easy as possible with our system, whether from coding, testing, feature design, and deployment process.
The process of what we are doing in factorio is very similar to system design and architectural choice concepts. We have to design and think systematically, if our factory architectural design is bad, there would be consequences waiting for you. Hard to maintain, really ugly and unorganized, hard to fix (aka debugging), etc. Thus, cascading effect is created.
Early game of factorio, everything works easily, no need to think about transport system, make it like spaghetti line is fine as long as it works. No consequences yet (for now).
Mid game, you want to scale your factory but suddenly it hit several limitations and bottlenecks. Adding more iron production breaks the copper workflow, belts are tangled, hard to trace the transportation line we designed. At the end, if your factorio empire (aka late game) already big enough, you want to make the material flow predictable, train networks are well-made for logistics side, and your circuit networks to have clear programmatic control and conditional logic. Hence, in factorio, it was about designing systems that are easy to maintain and control with and scale without you (intervening with it too much).
Similar to factorio, there are plenty programmatic mechanics you can leverage on minecraft using redstone as the main ingredient. Automatic farming system for waterflow on our farm and harvesting cronjob for our crops. Minecraft base defense system to combat zombies and skeletons automatically without your intervention. Organizing your inventory items automatically via connected programmed redstone on your chest inventories. Building secret door with piston via lever that connected using redstone for transport system efficiency (usually for long-distance travel such as cave exploring). The list goes on. All you need is knowing how redstone functions work and your blending skill between engineering and creativity works.
We can map out these video games example for our software engineering workflow with the help of current SOTA models. Fully-maximize the potential of LLMs without losing your creativity and thinking process. There is actually more video games that I could list here like terraria, but I think factorio and minecraft are enough and fitting examples here to share my idea about the mental models to be working with in present and the future of AI (no idea what kind of new innovation that will occur tbh).
Fundamental is More Important than Ever
Do you think with an LLM able to write all of the code means that you can develop fully-functional production-grade complex software? Are we vibing without knowing what is git, concurrency, time complexity (o(n), o(log n), etc), caching, an array, and data structures basic? (okay about time complexity, it’s not that important if we don’t need to think about performance or the user only ourselves)
Are we able to make secure web app by ourselves if we don’t even know how to store secrets such as an API key on .env? What if we git add . & git commit -m "lezgo" without .gitignore our .env with our precious API keys there?
Here is one of the lamest boring jokes that I actually hate right now because I have seen it multiple times but it’s the only joke I can think of regarding our current section:
 //////////////////////////////////////@fuckcomputer
//////////////////////////////////////@fuckcomputerYup, that’s right knowing the fundamental of programming, literal computer literate, know how to use git for version control, how API works, or fundamentally how computer and internet work. Know what http is, understand and familiar with data structures and algorithms, one of the core courses in computer science.
My point here is, yes you can vibecode all you want but please learn the fundamental. Use the LLM to augment your knowledge and also fulfill the knowledge gap too.
You don’t want to ruin your viral consumer app by leaking users’ data, including users’ selfies and photo ID like Tea, a dating advice app for women that went viral on Tiktok 2.
We still need to learn, not following LLM blindly even though current models are already good enough for yolo mode. Remember what I said before in previous section, the more knowledgeable we are, the better LLM output we can get. Even if it’s completely made-up hypothesis by myself, I believe learning (also strengthening) the fundamentals, and knowledge accumulation despite model intelligence that keeps improving will still benefit us in the long run. Especially our thought process and how we use LLM as a tool later on.
Here are books that keep appearing in discussions about programming fundamentals:
- Structure and Interpretation of Computer Programs
- Computer Systems: A Programmer’s Perspective
- The Art of Computer Programming
- Designing Data-Intensive Applications
There is also recommended reading for developers from the cofounder of stackoverflow itself, Jeff Atwood, that you can check here.
I won’t limit the fundamental in this context for computer science and software engineering literacy. But it dives deep to what you are working on such as react framework, golang, and any frameworks or programming languages you are using. I will use my past skill issue (actually till now) experience of working with react as an example:
Around 2024-2025, I had a case I’m working on edu startup as >part-time, working on authentication (especially user auth >schema validation) and making new user onboarding flow and >its modal. I had specific issue regarding react (I >forget what it is), but what I remember was I’m repeatedly >asking on cursor (claude sonnet 3.5(?)) about the problem and >its solution. Claude provided 4 solutions to solve the >problem I encountered and I was giving up, decided to ask my >friend that understands react instead. My friend proposed the >solution that I was looking for, tried to implement the >solution (with help of cursor too) and finally it worked.
This is one example of how important the fundamental is, not limited to “programming” only, basically on the scope of what you’re working on too. Of course, until now I have encountered several issues I have faced that I have to search manually through stackoverflow, reading the official docs, and asking my friends for help.
Practical Primitives
After we redefine the thinking process and mental models of approaching and working with these token-prediction slot machines, now let’s talk about the practical methods to work with these models that hopefully still relevant in the future as we are in transition era as AI disrupts current tech industry (or maybe a bubble, honestly idk man).
Context Engineering

Context engineering is broader than prompt engineering. Context engineering means that we hand the curated relevant context, including prompts, specific instructions, specific way, and relevant data in the limited context length of the model as we haven’t solved the memory problem in current model. Using MCP might overload the context window and consume additional tokens 3. We want to hand the context to the model with flexibility to be able to try everything 1.
MCP, agent skill, AGENTS.md, and tool calling are one of the ways to feed LLM proper and curated right amounts of context, not too much, enough to pull out the model output as much as possible by feeding an LLM precise right amounts of data, approach and instructions. Agent skill? It’s just markdown and script under the hood. RAG? Feeding right amounts of external data to make an LLM output more accurate, hallucinate less, and align with what we want.
There are multiple practical ways I could think of to do context engineering from the simplest form one. For example:
- Well-made
CLAUDE.mdorAGENTS.mdas agent entrypoint (global and project-scope) - Explicit constraints (ex: always use
bunnotnpm, don’t usetype=Anyalways definetypes) - Dump right relevant amounts of docs on
docs/then mention@docs/<relevant-docsper feature implementation - Breaking down big complex task into small subset tasks (modularization), no context overload. You may make the repo from the minimal/bare skeleton that works (kind of like MVP) then scale it from there.
You don’t really need claude skill, subagent, plugin, another MCP, claude code/opencode wrapper, or any tool most of the time, vanilla setup of claude code is fine. Adjust based on what you need, which is most of the time, context that an agent needs, not glue-ing and blatantly trying all of the tools because some people told you so as they said
wow this
< devtool >is very amazing, its gonna be gamechanging bro< insert pointing soyjak meme here >-random ai influencer
Also here is the claude code setup from the one, who initiated claude code in Anthropic, surprisingly vanilla enough (for me)
 Boris Cherny@bcherny
Boris Cherny@bchernyThe point of context engineering is to provide highest signal to noise ratio as much as possible to LLM. Noise will make the context bloated and irrelevant (context poisoning), as the “memory” of LLM still not fully-solved yet. RAG, search tool, spec/TDD, etc, all leads to the context & memory of an agent.
Feedback Loops as Infrastructure
An iteration. A feedback loop for an agent, to make sure that final output meets our requirements. An LLM generates wrong logic? Wrong datatype? Unit testing and typecheck of our verification process will catch this first then return back the verification result to an LLM to resolve the issue. We can model this as a learning iteration of building a model from training -> evaluation -> result -> feedback -> training again.
Here is hypothetical anatomy of a feedback loop as our foundation to use it as infrastructure of our agentic workflow:
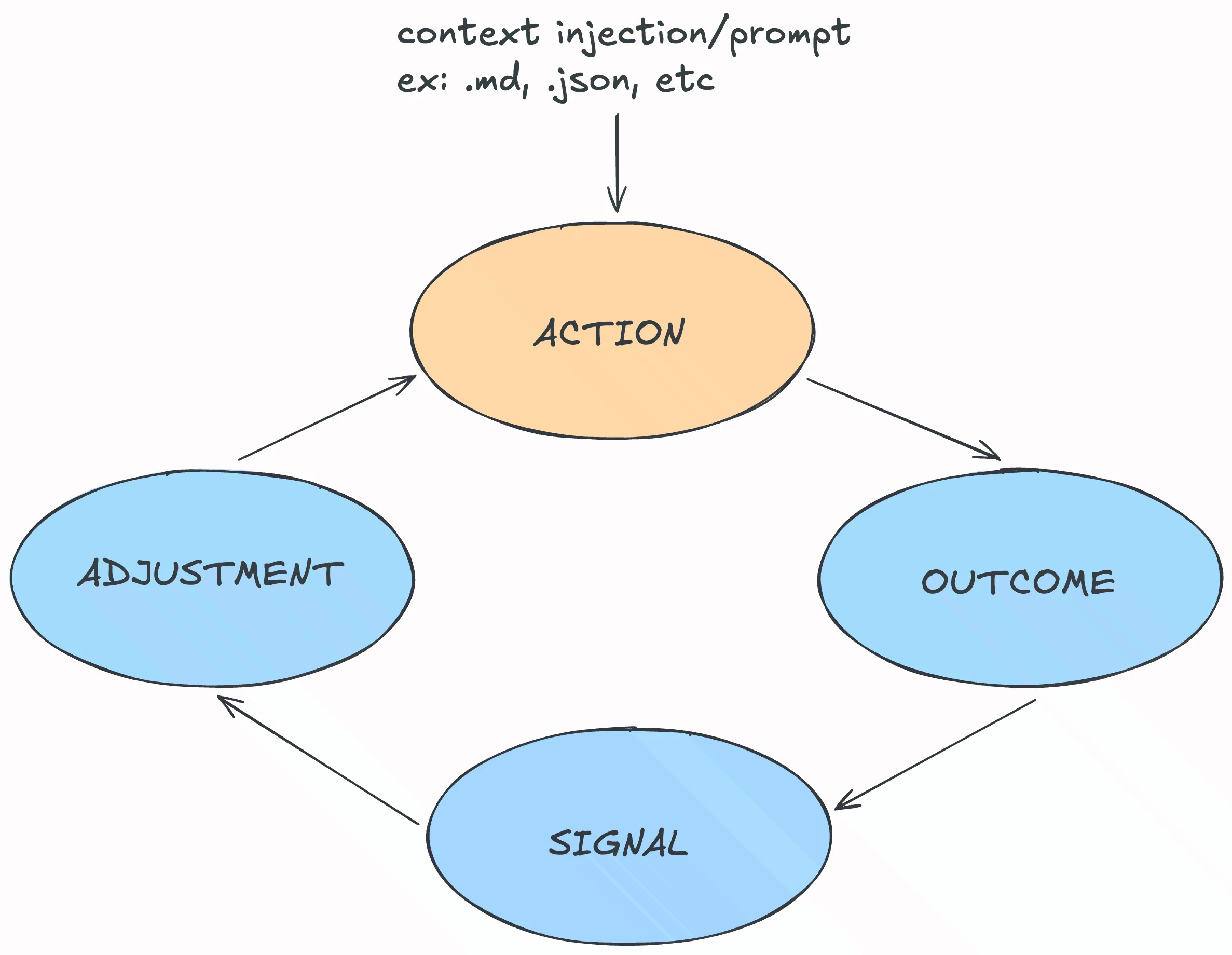
- Action: action means *whats being attempted here?** Specification of your software requirements, feature specification, PRD, or your detailed prompt/instruction for an LLM as markdown file can be classified as an action here.
- Outcome: literally the result of action we specified before. Result of the code written by an LLM with our instruction.
- Signal: what does the outcome tell us about the action we took? This is where we know whether our code that we generated through an LLM is correct or not. It shows clear error message, our verification layer caught the bug/error or at least we know that it didn’t work once we executed the code if our “signal” part is not good enough.
- Adjustment: targeted fix based on the signal part. An LLM is able to know what went wrong based on the signal output such as suggested fix from the verification layer, typecheck error, error logs from the backend, code execution logs, and the testing results. If the adjustment part was designed badly, an LLM will do random guessing what went wrong on the code when it generates error, not properly knowing the root cause and do targeted fix/adjustment.
Assume that I want to ship software as fast as possible while the code generated by an LLM is correct and high quality enough. Not some extremely slop bloated piece of code with hard-coded secret stored directly in code. To tackle this, we want to design the feedback loop design with:
- instant feedback
- tight loop
- strict coding standards/styles
- automated testing(?)
The variable we can control to achieve those goals are loop speed and signal clarity. Clear and precise signal, faster workflow, and targeted fixes, we don’t need to re-prompting to the agent, let the agent consume the code execution logs/results directly as their memory for next action iteration.
Instead of <le input spec and prompt.md here> -> agent writes code -> we review the code -> "claude, this is wrong, pls fix blabla" -> "agent rewrites" -> we review it again next day -> <till the code working perfectly fine>;
We could go something like this:
<le input spec/prompt.md> -> agent writes code -> tests run instantly through our verification layer -> "expected X, got Y instead at line 67" -> agent fixes immediately from the output -> tests pass
Clear and precise signal, faster workflow, and targeted fixes, we don’t need to re-prompting to the agent, let the agent consume the code execution logs/results directly as their memory for next action iteration.
Also comparing the feedback loop above, we can see clearly that the second loop is not only faster but also more automated, we are removing ourselves from the loop compared the first one. We are the bottleneck and the slowest part of the feedback loop (unironically lol). With second loop design, we pushed as much strict verification layers as possible with clear signal from the verification layer itself to be fed to an agent for next action iteration. We make the judgement call in the first part only, in the first iteration, not every iteration cycle.
Recently, there’s a simple yet surprisingly effective loop design that I can provide as an example here. Let me introduce ralph loop, introduced by Geoffrey Huntley in last year but it went viral this year.
It’s literally just a bash loop 4,
while :; do cat PROMPT.md | claude --dangerously-skip-permissions ; done
The idea is claude or any code agent executes the same prompt over and over again repeatedly in continuous loop until it meets completion criteria. There was claude official plugin for ralph loop. Since it was very buggy plugin, think it was deleted from official plugin by the anthropic staff but you can check the deepwiki of the plugin here.

Accidentally this ralph loop design pattern is one of the great examples of the feedback loop as infrastructure here. Each iteration sees the results of all previous iterations; reads the current states of file/code changes, sees what was done before, and builds incrementally on previous work aka self-referential context accumulation.
Iteration 1: Initial implementation attempt → creates files
Iteration 2: Reviews own work → identifies issues → fixes
Iteration 3: Further refinements → handles edge cases
Iteration N: Detects completion criteria → terminates| default approach | ralph loop approach |
|---|---|
| human reviews each step | loop IS the review mechanism |
| feedback requires intervention | feedback is automatic via filesystem state |
| progress requires prompting | progress is continuous until completion |
| infrastructure supports feedback | infrastructure is feedback |
I made ralph loop script (well actually generated by opus 4.5 xd) for my nixos vm with clan framework as module here:
modules/ralph-script/
├── PROMPT.md.example
├── default.nix
└── ralph.shthe ralph loop bash script (extended):
set -euo pipefail
PROMPT_FILE="PROMPT.md"
MAX_ITERATIONS=0 # 0 = unlimited
DELAY_SECONDS=0
COMPLETION_PROMISE=""
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
NC='\033[0m' # No Color
# Parse command line arguments
while [[ $# -gt 0 ]]; do
case $1 in
--prompt)
PROMPT_FILE="$2"
shift 2
;;
--max)
MAX_ITERATIONS="$2"
shift 2
;;
--delay)
DELAY_SECONDS="$2"
shift 2
;;
--promise)
COMPLETION_PROMISE="$2"
shift 2
;;
--help|-h)
usage
exit 0
;;
*)
echo "Unknown option: $1"
usage
exit 1
;;
esac
done
# Allow environment variables to override if args not provided
PROMPT_FILE="${PROMPT_FILE:-PROMPT.md}"
MAX_ITERATIONS="${MAX_ITERATIONS:-0}"
DELAY_SECONDS="${DELAY_SECONDS:-0}"
COMPLETION_PROMISE="${COMPLETION_PROMISE:-}"
# Validate prompt file exists
if [[ ! -f "$PROMPT_FILE" ]]; then
echo -e "${RED}Error: Prompt file '$PROMPT_FILE' not found${NC}"
echo "Create a PROMPT.md file with your task, or specify one with --prompt"
exit 1
fi
# Check if claude is available
if ! command -v claude &> /dev/null; then
echo -e "${RED}Error: 'claude' command not found${NC}"
echo "Please install Claude Code CLI first"
exit 1
fi
# Trap CTRL+C for graceful shutdown
trap 'echo -e "\n${YELLOW}=== Ralph Loop interrupted ===${NC}"; exit 0' INT
# Print startup info
echo -e "${BLUE}=== Ralph Loop Starting ===${NC}"
echo -e "Prompt file: ${GREEN}$PROMPT_FILE${NC}"
echo -e "Max iterations: ${GREEN}${MAX_ITERATIONS:-unlimited}${NC}"
[[ $DELAY_SECONDS -gt 0 ]] && echo -e "Delay between iterations: ${GREEN}${DELAY_SECONDS}s${NC}"
[[ -n "$COMPLETION_PROMISE" ]] && echo -e "Completion promise: ${GREEN}$COMPLETION_PROMISE${NC}"
echo -e "${BLUE}===========================${NC}"
echo ""
# Main loop
iteration=0
while true; do
((iteration++))
echo -e "${BLUE}=== Ralph Iteration $iteration ===${NC}"
echo -e "${YELLOW}$(date '+%Y-%m-%d %H:%M:%S')${NC}"
echo ""
# Run claude with the prompt
# Using --dangerously-skip-permissions for fully autonomous operation
# Using --print to get output for completion detection
if [[ -n "$COMPLETION_PROMISE" ]]; then
# Capture output for promise detection
output=$(cat "$PROMPT_FILE" | claude --dangerously-skip-permissions --print 2>&1) || true
echo "$output"
# Check for completion promise
if echo "$output" | grep -qF "$COMPLETION_PROMISE"; then
echo ""
echo -e "${GREEN}=== Completion promise detected! ===${NC}"
echo -e "Total iterations: $iteration"
exit 0
fi
else
# No promise detection, just run
cat "$PROMPT_FILE" | claude --dangerously-skip-permissions || true
fi
echo ""
echo -e "${BLUE}=== Iteration $iteration complete ===${NC}"
# Check max iterations
if [[ $MAX_ITERATIONS -gt 0 ]] && [[ $iteration -ge $MAX_ITERATIONS ]]; then
echo ""
echo -e "${YELLOW}=== Max iterations ($MAX_ITERATIONS) reached ===${NC}"
exit 0
fi
# Optional delay
if [[ $DELAY_SECONDS -gt 0 ]]; then
echo "Waiting ${DELAY_SECONDS}s before next iteration..."
sleep "$DELAY_SECONDS"
fi
echo ""
doneKey points:
--promise TEXT: Completion detection via magic string (e.g.,COMPLETE )--max N: Safety limit on iterations--delay N: Rate limiting between iterations (it’s not really needed, optional flag)
When you make a prompt, whether as a direct prompt on interface or as a markdown file. We only need two things:
- Task, what you want done
- Completion Criteria, when done, output:
FINISHorDONE
An example:
## Your Task
Build a REST API for a todo application.
## Requirements
1. CRUD operations for todos (create, read, update, delete)
2. Input validation for all endpoints
3. Proper error handling
4. Unit tests with >80% coverage
5. API documentation in README
## Completion Criteria
When ALL of the following are true, output `<promise>COMPLETE</promise>`:
- All CRUD endpoints are implemented and working
- Input validation is in place
- All tests pass
- Coverage is >80%
- README has API documentationyou can also add an addition such as:
## Iteration Strategy
Each iteration you should:
1. Check the current state of the project (run tests, check for errors)
2. Identify what needs to be done next
3. Implement one focused improvement
4. Verify your changes work
## Important
- Work incrementally - don't try to do everything at once
- Run tests frequently to catch issues early
- If stuck, re-read the requirements and try a different approach
- Output `<promise>COMPLETE</promise>` ONLY when ALL criteria are metFrom a simple claude wrapper bash script we made, we can invoke the ralph loop with something like ./ralph.sh --promise "DONE" --max 50 which is the completion signal is when an LLM invokes <promise>DONE</promise> to end the iteration and signal that coding process is finished with 50 iterations as the limit.
There is also examples from awesomeclaude.ai based on claude official plugin that already deleted:
# feature implementation
/ralph-loop:ralph-loop "Implement [FEATURE_NAME].
Requirements:
- [Requirement 1]
- [Requirement 2]
- [Requirement 3]
Success criteria:
- All requirements implemented
- Tests passing with >80% coverage
- No linter errors
- Documentation updated
Output <promise>COMPLETE</promise> when done." --max-iterations 30 --completion-promise "COMPLETE"# TDD development
/ralph-loop:ralph-loop "Implement [FEATURE] using TDD.
Process:
1. Write failing test for next requirement
2. Implement minimal code to pass
3. Run tests
4. If failing, fix and retry
5. Refactor if needed
6. Repeat for all requirements
Requirements: [LIST]
Output <promise>DONE</promise> when all tests green." --max-iterations 50 --completion-promise "DONE"There is more examples you can check out directly on awesomeclaude.ai as usage references.
As ralph loop is current design pattern meta for vibecoding, maybe in the future there might be change there will be a better design pattern emerging as model capabilities and intelligence will improve. Nevertheless, my point still intact. Ralph loop is an example of the feedback loop as foundational design pattern for agentic workflows.
Now get back to the feedback loop itself. This means that to make our code verification fast and strict, so it’s more predictable and straightforward to see whenever our code works or not. What we can do are:
- Type checkers and linters as verification layer that you can put it on your pre-commit hook or pre-push hook as gitops for instant feedback/signal. Ex:
nix fmtandnix flake check. - Fast infrastructure system, as code generation become much faster than before, we also need CI/CD pipeline that doesn’t take too long to run. We need faster build that fails with clear error if possible in seconds.
- Small, scoped tasks as smaller action outputs to faster outcomes, thus quicker adjustment -> faster loop cycle. Not one shotting in a session (modularization is keypoint here).
- Test as the feedback mechanism for clear signal.
- Make failure cheap, build the sandbox, define good version controlling (aka gitops), easy rollback. Run claude yolo mode on sandbox (containerized).
- Use strict languages. Will write more about this in the next section.
Verification > Trust
You’re absolutely right
That’s what it said, trust no one, an agent or yourself, verify the code, test the code as what I wrote earlier on previous section.

You have heard about this often. That’s right. You’re indeed absolutely right. You can say the most wrong statement anyone has ever heard and yet claude will glaze you with you’re absolutely right. They (agents) are confident while frequently wrong. The correct way to tackle this is verify by default.
Verification layers:
- Type systems (catch structural errors)
- Tests (catch behavioral errors/logical errors)
- Linters/formatters (catch style errors)
- Second opinion of agent (catch logic errors if tests are not enough, usually for complex logic)
- Ourself (judgement, true verification layer)
Verification layers help us save time to review code that actually needs to be judged properly, we don’t need to waste our time to review all of the code manually. There is one more verification layer that might be important in the future, language choice.
Language Choice as Verification Strategy
This section is highly opinionated, I might be very wrong here. Purely hypothesis especially for future trained LLM preparation. Take it with a grain of salt..
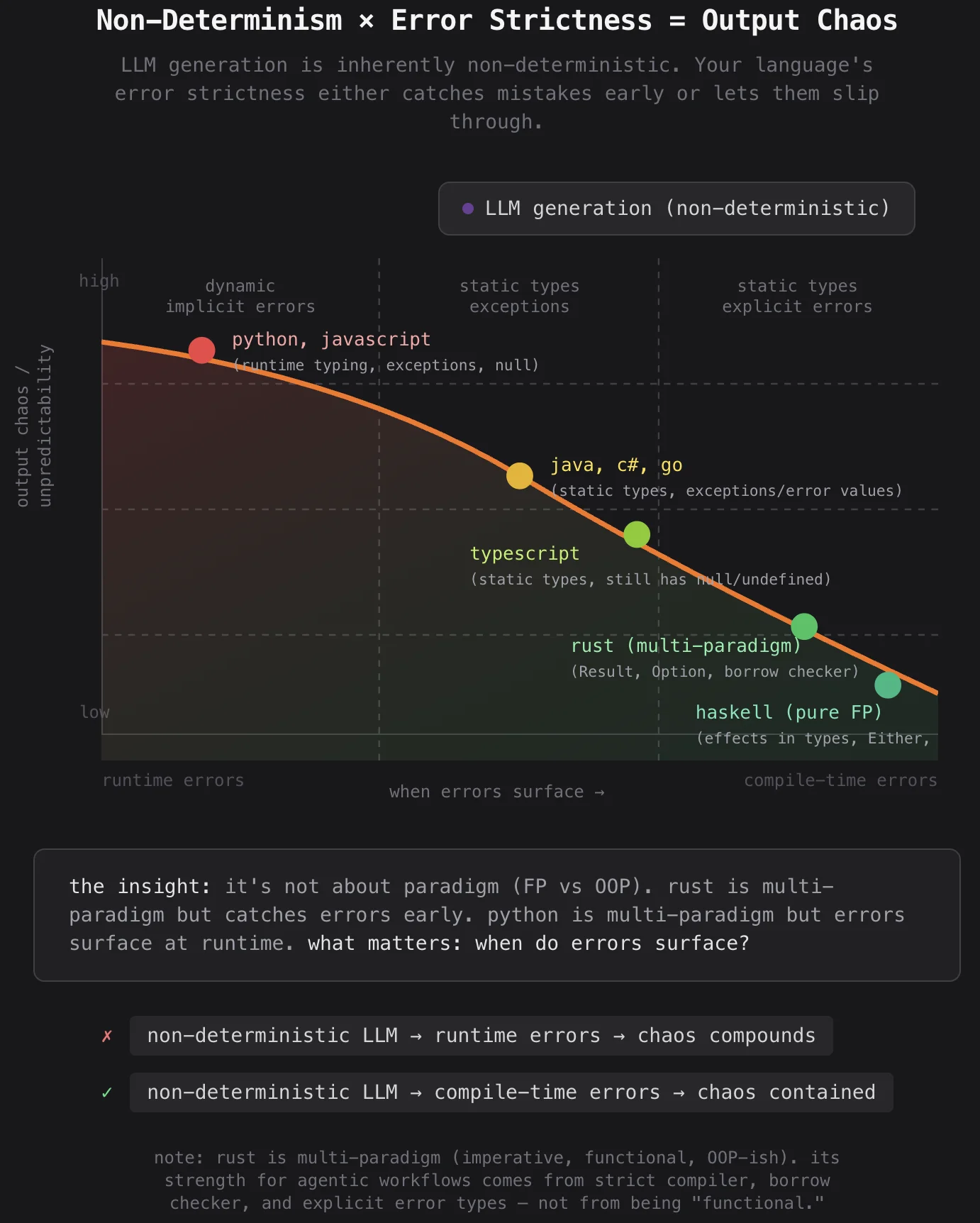
LLM is non-deterministic, it’s a slot machine that predicts the next tokens based on the input. A prediction, so the output is more likely probabilistic. Okay now imagine we are using OOP, it varies in determinism. There are deep inheritances and mutable state everywhere. It might compound chaotic effects.
So my hypothesis here is that the combination matters:
- non-deterministic generator + deterministic paradigm = chaos contained
- non-deterministic generator + non-deterministic paradigm = chaos compounds
| Paradigm | Determinism | Why |
|---|---|---|
| Pure FP + strict types | High | f(input) → output, always same. No side effects. Compiler enforces correctness. |
| Strict static typing | High | Multi-paradigm but compiler catches errors before runtime. Ownership, borrowing, strong type inference. (Rust, Go) |
| FP + dynamic types | Medium-high | Pure functions, but type errors surface at runtime |
| Imperative + strict types | Medium | Predictable control flow, but mutable state adds complexity |
| OOP + strict types | Medium-low | Inheritance, polymorphism, state — multiple ways to be subtly wrong |
| OOP + dynamic types | Low | State + inheritance + runtime typing = many degrees of freedom for bugs |
Alright here we go, let’s start another programming language discourse, FP vs OOP, rust vs python, etc. You can disagree with me, I don’t really mind as my current state is framework/proglang agnostic and I’m leaning to software correctness so as long as there is the programming method that I found lean to more correctness while being simple, pragmatic, and effective, I will switch, learn, and try to adapt to it.

As an LLM returns non-deterministic output, why would you code something that’s non-deterministic again rather than deterministic and purely declarative leaning language? This is where nix fixes this.
At least writing generating functional programming styled code is more predictable than writing OOP code as we eliminate potential bugs as much as possible by decreasing side effects that might occur (even though there is still possibility of hidden bug later on).
This is why I’m betting myself to learn and lean towards more on declarative, functional programming way, also more focusing on language with less abstraction layer, more performance-focused, maybe less resource intensive (less bloated) too. I already abstract my way of coding using natural language to the probabilistic machine, why would I instruct the probabilistic machine to write dynamic unpredictable, more abstracted, programming language?
We wrote in programming languages that are more understandable and there is more abstraction combined with plenty of optimized ready-to-use libraries and frameworks with python and javascript (also php with laravel). Usually these programming languages were used by startups or new companies to develop and ship their product as fast as possible. Do current SoTA LLMs write high quality C/C++ or rust?
First, take a look at top programming languages on github from github octaverse 2024 5 and github octaverse 2025 6:


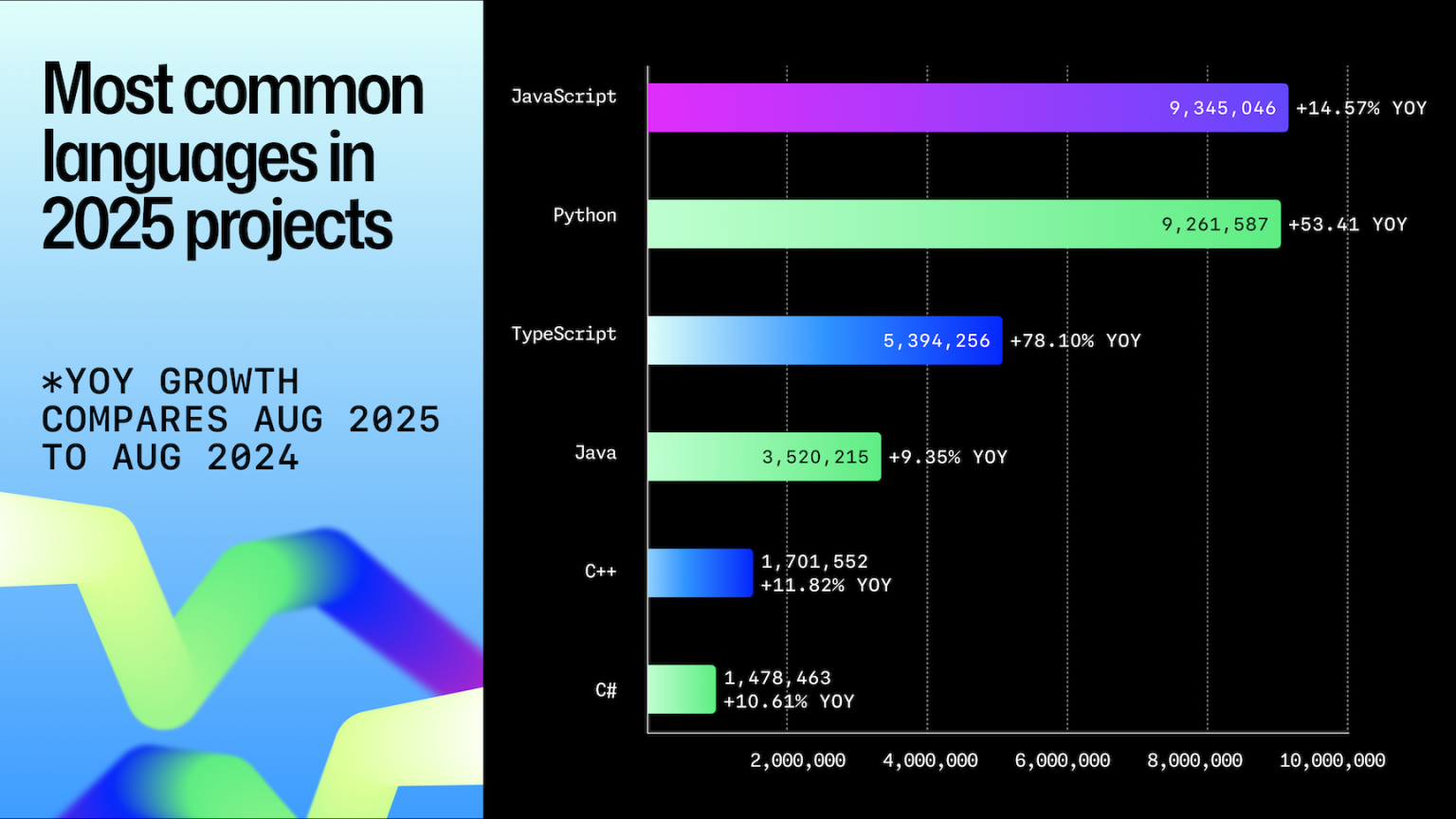
As most of github codebases are dominated by python and typescript/javascript. I assume that LLMs are really great at writing dynamic type programming language (python and javascript) as there is more variety of codebase, more data trained on, and more examples of code to learn from. Even though the codebases including both bad written code and best-implementation of “the way” or “correct” way of writing code. I also assume these AI frontier giants curated their coding dataset especially anthropic, to make their LLM to be good at coding.
Well, there is also survey conducted by stackoverflow, the quora of programming, one of the biggest programming dataset providers on the internet 7. I also believe that (or maybe quite obvious) stackoverflow’s datasets are higher quality and more curated than github codebases itself because we want the user answer as de facto right answer (via most voted+verified answer sign) to the related question in the context of programming.
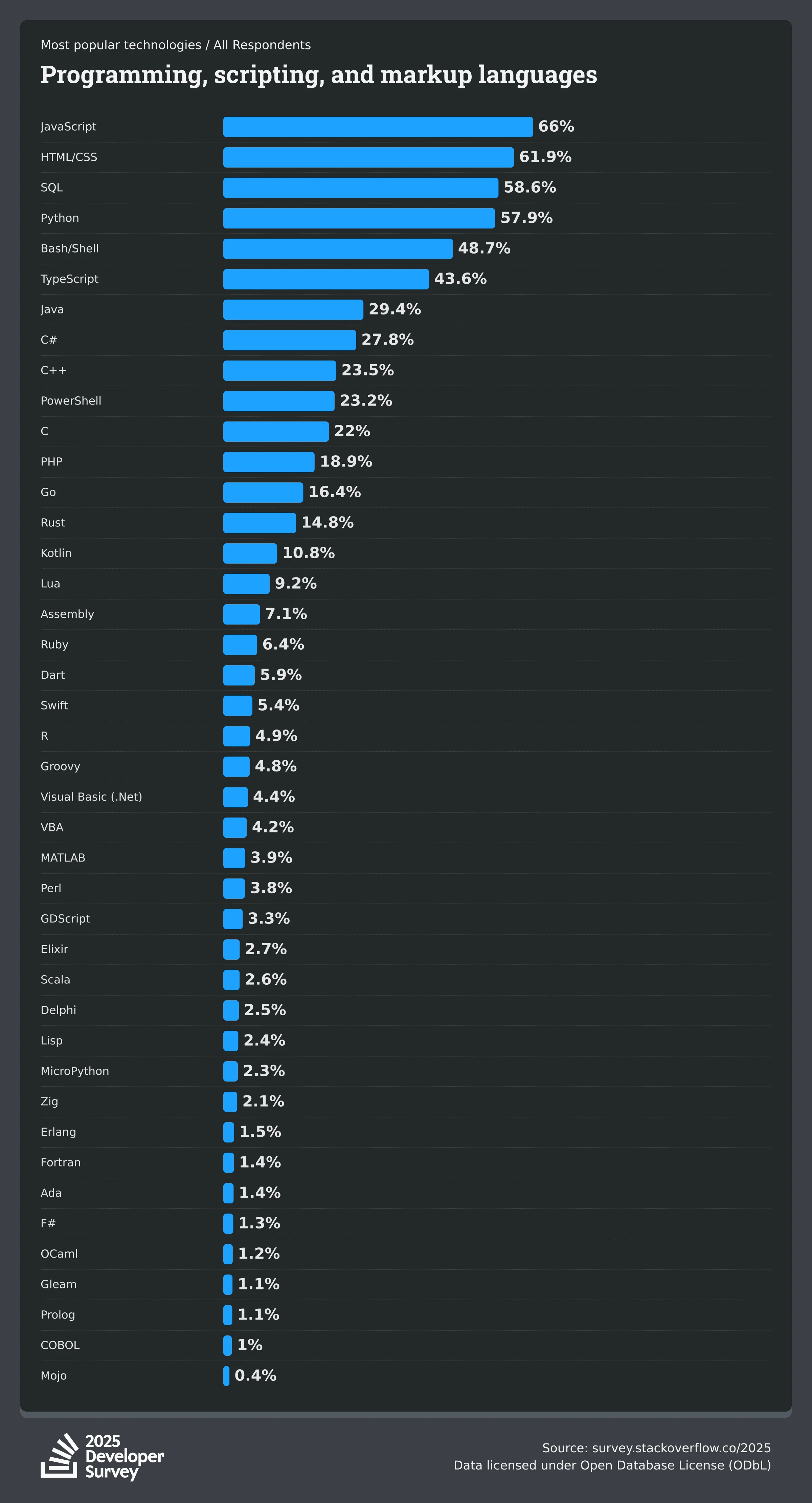
We can conclude that the biggest training dataset from last year is javascript, then followed by python and typescript.
Despite that, some said that opus 4.5 is already extremely smart and good at rust already.
 Dioxus 🧬@dioxuslabs
Dioxus 🧬@dioxuslabs cache crab@cachecrabcache crab@cachecrab
cache crab@cachecrabcache crab@cachecrab Zed@zeddotdev
Zed@zeddotdev
 Igor Babuschkin@ibab
Igor Babuschkin@ibabThose tweets I embedded here are including one of the popular app framework, dioxus and from zed itself (an IDE written in rust). Also mentioning founding engineer of helixdb, a popular database written in rust and co-founder of xAI itself which I believe they are pretty good at writing rust before (I mean they have credibility here).
As you can write generate code (at least a boilerplate) with initial steep learning curve programming languages like rust, nix, and haskell with help of an LLM, I don’t think that in the future, we need to use python or javascript to speedup our development process as we can benefit these language performance benefits as Igor said in tweet above.
TypeScript grew by over 1 million contributors in 2025 (+66% YoY), driven by frameworks that scaffold projects in TypeScript by default and by AI-assisted development that benefits from stricter type systems.
Last year report of GitHub Octoverse supports my thesis about strict verification matters, especially when code generation itself is non-deterministic as type-safe javascript mogged beat python growth last year. We can see that despite historically javascript being dynamic, the trend is toward strictness.
And libraries like effect.ts are bringing typescript ecosystem to more strictness and adapting to heavy FP pattern including immutability by default, composable, pure functions, typed-errors, and explicit side effects management.
While Effect makes usage of Functional Programming principles >and patterns internally you can be proficient in Effect by >simply using it as a smart Promise and forget that there is >even a thing called Functional Programming
My thesis is languages with strict, fast feedback loops will disproportionately win the agentic era (present-to-future).
Declarative Systems as Agentic Playgrounds
We want to sandbox our agent environments where agents can experiment and operate safely inside our environment. The ideal sandbox is explicit state, purely isolated, easy rollback, clear error, and easily reproducible. So you can run claude --dangerously-skip-permissions without overthinking what might happen once it does something stupid.
To make declarative configuration sandbox for the agent, we can use something like docker, terraform, or kubernetes (for multiple-nodes environments). However, guess what?
Nix fixes this
| Tool | Declarativeness | The catch |
|---|---|---|
| nix | pure | config → system is a pure function. same input = same output, always. |
| terraform | high | declarative HCL, but has a state file. state can drift from reality. |
| kubernetes | intent-based | you declare desired state, controllers reconcile. but debugging “why isn’t it converging?” is opaque. |
| docker compose | structural | declares service topology, but underlying images may not be reproducible. |
| dockerfile | mostly imperative | RUN apt-get update — order matters, results vary over time. layers are cached, not content-addressed. |
Ideally (and personally), to run an agent as wild as possible in dedicated environment, I want to make the “environment” versatile and flexible, we can assign it to systemd, or containerized it with docker/podman, or maybe assign and set it up for orchestration systems (like kubernetes) while still being fully-declarative, remain “infrastructure as a code” for easy reproducibility and machine management. This is where using nix shines for me.
I can configure declaratively, creatively using several frameworks, tools, combined with other programming languages with nix. Nix isn’t only functional programming language, it’s also a purely functional package manager tool and system configurator too. The core model of nix is:
configuration nix -> nix builds -> /nix/store/<hash>-result
Same input, same output. The stored path is always isolated through /nix/store, which is a content-addressed file system.
| property | what it means | why agents love it |
|---|---|---|
| purity | no side effects during build. no network calls mid-build (unless explicitly declared). | reproducible. agent can retry infinitely with same result. |
| content-addressed store | every build artifact is hashed by its inputs. /nix/store/abc123-... | no “it worked yesterday.” either the hash matches or it doesn’t. |
| atomic operations | upgrades/rollbacks are instant. switch a symlink. | no “rolled back.” build environment is explicit. |
| hermetic builds | builds happen in isolated sandboxes. no access to global state. | no “it worked on my machine.” build environment is explicit. |
| declarative system config | configuration.nix describes your entire system. | change config → rebuild → entire system matches declaration. |
| flakes | locked dependencies, reproducible entry points. | nix develop gives exact same shell everywhere. agent doesn’t deal with “wrong version” issues. |
Sandboxing in nix is very flexible as we can isolate multiple layers of our choice from the computer system/kernel, network, filesystems, application, write-access, until application-layer. Almost everything can be declared and configured in nix.
Build environment:
├── No network access (unless explicitly allowed)
├── No access to /home, /tmp, or anything outside declared inputs
├── Read-only access to dependencies in /nix/store
├── Write access only to build output directory
└── Isolated /etc, /usr, etc.This means:
- agent can’t accidentally break your system during a build (unless there is wrong configuration/method)
- agent can’t rely on hidden state
- if it builds in the sandbox, it (should) build anywhere, reproducibility guarantee (98%, i’m not that confident)
There are multiple patterns with a goal, to make customized sandbox on nix. Example:
- nix shell (one-off experiments)
- dev shell (nix develop)
- nixos vm (nixfied linux distro)
I have been experimenting with nixos vm to build a customized agent playgrounds using clan since last year and it’s been fun so far. I can customize and vibecode bunch of features without fear of breaking my machine and make my agent operate wildly.
Okay maybe it’s too biased and too specific now as we are explaining about nix instead of higher abstraction for how we interact and work with AI from present to the future. Literally contradicts what I wrote earlier in the first place. Currently, I use nix as devops and infra system for most of my workflow as aligned as it is with my mental models of working with AI agent itself. It might change in the future if there are any better alternative programming languages that suitable for environment and infrastructure building for agent playgrounds. This is also my bet that nix ecosystem will do really well personally because of current state of AI-powered coding and development.
Environment as Interface
Now let’s redefine how we interact and work with an LLM. If opus writes all of our code, and we use something like another claude or coderabbit to review our PR and code, do we need a laptop? If our current workflow is more like reviewing and verifying the code, we don’t really need IDE at all?
Why would we need to use IDE then? Why are we opening VSCode just to read and review the code? Do we really need code editor as an interface for development workflow?
My Current Setup
Recently, I’ve been exploring and experimenting with my own nixos vm (using clan framework) derived from baremetal server I bought last year as agent-first dev vm. I wonder how I’d still be able to ship some code through phone in hand. It should come in handy when I was on public transport or anywhere, right??
The idea is simple (and unoriginal), I believe that a bunch of people have already set up this workflow anyway.
my phone -> connect to tailscale vpn -> ssh agent@nixos-vm via termius -> run claude inside termius
It’s quite simple, but I want it more accessible, especially the UX part, why would I open terminal then run ssh on my phone? Then I tried to integrate claude code with my telegram as telegram bot is easier to set up (via BotFather) rather than whatsapp or discord (personally).
Isn’t there claude code on claude mobile app?
I want to make it more customizable for me, fit my workflow, not limited to my own github, I might make claude as a personal sysadmin my dev vm too so I decide to integrate it with my telegram directly.
There are two ways of integrating claude code with telegram:
- claude code cli command (ex:
claude -p "pls implement auth") - using agent sdk
I’m ending up using two of these methods anyway.
So, fast-forward here is my current personal dev vm setup and its system visualization with mermaid.js graph that I made by asking to claude code since I’m too lazy to make it myself from scratch on excalidraw (I also asked claude to make mermaid graph wrapper component for my blog immediately as I’m writing this blog),
flowchart TB
subgraph Phone["📱 iPHONE"]
Termius["🖥️ Termius<br/>SSH Client"]
TelegramApp["💬 Telegram<br/>Bot Interface"]
end
subgraph Network["🌐 MESH NETWORK"]
Tailscale["🔗 Tailscale VPN<br/>100.x.x.x<br/>P2P Encrypted"]
TelegramAPI["📡 Telegram API<br/>api.telegram.org"]
ZeroTier["🌍 ZeroTier VPN<br/>Backup Network<br/>Controller: greencloud"]
end
subgraph DalangDev["🖥️ DALANG-DEV (NixOS KVM VM)"]
subgraph Systemd["⚙️ SYSTEMD SERVICES"]
Bot["🤖 claude-telegram-bot<br/>TypeScript/Node.js<br/>/claude /spawn /sessions<br/>/switch /send /output /kill"]
Hooks["🪝 claude-hooks-setup<br/>settings.json generator"]
Notify["📢 claude-notify<br/>Telegram notifier"]
TailscaleD["🔐 tailscaled"]
ZeroTierD["🌍 zerotier-one"]
end
subgraph Execution["🚀 AGENT EXECUTION"]
Parallel["⚡ Parallel Claude Engine<br/>tmux + git worktrees<br/>Max 10 sessions<br/>/var/lib/claude-parallel"]
Ralph["🔄 Ralph Loop<br/>Autonomous iterations<br/>ralph --max 50 --promise OK<br/>Reads PROMPT.md"]
end
subgraph Agents["🧠 AI AGENT TOOLS"]
Claude["💜 Claude Code<br/>Opus 4.5 / Sonnet 4<br/>from llm-agents"]
OpenCode["🟢 OpenCode<br/>Gemini 3 Pro/Flash<br/>Antigravity plugin"]
Codex["🔵 Codex<br/>GPT-4 / o1<br/>OpenAI"]
end
subgraph Sandbox["🛡️ BUBBLEWRAP SANDBOX"]
RW["📝 READ-WRITE<br/>/home/agent/workspace<br/>/tmp /var/tmp"]
RO["🔒 READ-ONLY<br/>/ ~/.ssh ~/.gitconfig<br/>~/.claude ~/.config/opencode"]
end
subgraph Tools["🛠️ DEV TOOLS"]
NixVim["📝 NixVim<br/>LSP: nixd, pyright<br/>ts_ls, gopls, rust_analyzer"]
GitTools["🔀 Git Tools<br/>git, gh, jj, lazygit, tea"]
DevEnv["📦 Dev Env<br/>direnv, devenv, uv<br/>Python 3, nushell"]
end
subgraph Security["🔐 SECURITY LAYER"]
SSH["🔑 SSH Hardening<br/>Key-only, curve25519<br/>chacha20-poly1305"]
Firewall["🧱 Firewall<br/>TCP 22, UDP 9993"]
Kernel["🐧 Kernel Hardening<br/>SYN cookies, rp_filter"]
end
end
subgraph Remotes["☁️ GIT REMOTES"]
GitHub["🐙 GitHub<br/>0xrsydn"]
Forgejo["🔧 Forgejo<br/>git.rasyidanaf.com<br/>96.9.212.43"]
end
Phone --> Network
Termius --> Tailscale
TelegramApp --> TelegramAPI
Tailscale --> DalangDev
TelegramAPI --> Bot
ZeroTier --> DalangDev
Bot --> Parallel
Bot --> Notify
Parallel --> Agents
Ralph --> Agents
Agents --> Sandbox
Hooks --> Notify
Sandbox --> Tools
Tools --> Security
GitTools --> RemotesThe claude telegram bot flow:
sequenceDiagram
participant iPhone as 📱 iPhone Telegram
participant API as 📡 Telegram API
participant Bot as 🤖 claude-telegram-bot
participant Tmux as ⚡ tmux session
participant Claude as 💜 Claude Code
participant Hooks as 🪝 claude-hooks
participant Notify as 📢 claude-notify
iPhone->>API: /claude "fix the auth bug"
API->>Bot: Webhook message
Bot->>Tmux: Spawn new session
Tmux->>Claude: Execute in sandbox
Claude->>Claude: Read files, write code
Claude->>Claude: Run tests, commit
Claude->>Hooks: SessionEnd trigger
Hooks->>Notify: Send notification
Notify->>API: POST message
API->>iPhone: "✅ Task complete!"
Note over iPhone,Claude: Parallel Sessions
iPhone->>API: /spawn feature-branch
API->>Bot: Create new worktree
Bot->>Tmux: New tmux window
iPhone->>API: /sessions
API->>Bot: List active
Bot->>API: "Session 1: main, Session 2: feature-branch"
API->>iPhone: Show sessions
iPhone->>API: /switch 2
Bot->>Tmux: Attach to session 2SSH access via termius
flowchart LR
subgraph Phone["📱 iPhone"]
Termius["🖥️ Termius"]
end
subgraph Option1["Option 1: ProxyJump"]
MacBook["💻 MacBook<br/>Jump Host"]
end
subgraph Option2["Option 2: Direct Tailscale SSH"]
TailscaleSSH["🔗 Tailscale SSH<br/>--ssh mode"]
end
subgraph Target["🖥️ dalang-dev"]
VM["NixOS VM<br/>root@nixos-dev"]
end
Termius -->|"Tailscale VPN<br/>100.x.x.x"| MacBook
MacBook -->|"ProxyJump<br/>SSH"| VM
Termius -->|"Direct<br/>100.x.x.x"| TailscaleSSH
TailscaleSSH -->|"Identity Auth<br/>No password"| VM
style Option2 fill:#2d5a27,stroke:#4ade80Sandbox security model
flowchart TB
subgraph Outside["🌍 OUTSIDE SANDBOX"]
Agent["👤 agent user"]
Commands["$ sandbox-claude<br/>$ sandbox-opencode<br/>$ sandbox-codex"]
end
subgraph Bubblewrap["🛡️ BUBBLEWRAP NAMESPACE"]
subgraph ReadWrite["📝 READ-WRITE (tmpfs)"]
Workspace["/home/agent/workspace<br/>Code lives here"]
Tmp["/tmp<br/>/var/tmp<br/>/run/user"]
end
subgraph ReadOnly["🔒 READ-ONLY BINDS"]
Root["/ (root filesystem)"]
SSH["~/.ssh<br/>Git credentials"]
GitConfig["~/.gitconfig"]
ClaudeConfig["~/.claude<br/>API keys"]
OpenCodeConfig["~/.config/opencode"]
end
subgraph Allowed["✅ ALLOWED"]
Network["🌐 Network Access<br/>git push/pull<br/>API calls"]
end
subgraph Blocked["❌ BLOCKED"]
Destructive["rm -rf /<br/>System modifications<br/>Write outside workspace"]
end
end
Agent --> Commands
Commands --> Bubblewrap
ReadWrite --> Allowed
ReadOnly --> Allowed
style Blocked fill:#7f1d1d,stroke:#ef4444
style Allowed fill:#14532d,stroke:#22c55eAnd last.. clan module structure diagram..
flowchart TB
subgraph Clan["🏠 CLAN FRAMEWORK"]
FlakeNix["flake.nix<br/>Entrypoint"]
ClanNix["clan.nix<br/>Inventory & Instances"]
end
subgraph Machine["🖥️ machines/dalang-dev/"]
Config["configuration.nix"]
Disko["disko.nix<br/>Disk layout"]
Facter["facter.json<br/>Hardware facts"]
end
subgraph Modules["📦 modules/"]
AITools["ai-tools.nix<br/>Claude, OpenCode, Codex"]
Sandbox["agent-sandbox.nix<br/>Bubblewrap isolation"]
AgentGit["agent-git.nix<br/>Git & SSH config"]
Hooks["claude-hooks.nix<br/>Event hooks"]
Notify["claude-notify.nix<br/>Telegram alerts"]
Parallel["parallel-claude/<br/>Multi-session support"]
RalphScript["ralph-script/<br/>Autonomous loop"]
NixVimMod["nixvim.nix<br/>Neovim + LSP"]
Dev["dev/<br/>git-tools, tmux, devenv"]
end
subgraph Services["🔧 services/"]
TelegramBot["claude-telegram-bot/<br/>Telegram Bot Service"]
end
FlakeNix --> ClanNix
ClanNix --> Machine
ClanNix --> Services
Config --> Modules
Config --> AITools
Config --> Sandbox
Config --> AgentGit
Config --> Hooks
Config --> Notify
Config --> Parallel
Config --> RalphScript
Config --> NixVimMod
Config --> DevThis is my own personal setup, I’m not going to say that this is best practice or whatever it is, but I want to redefine and make my workflow much simpler and effective at the end of the day.
Termius + tailscale + VM setup of mine..
 dogfiles@0xrsydn
dogfiles@0xrsydn
And few showcases of my telegram bot utilizing both claude cli and an agent sdk..
dogfiles@0xrsydn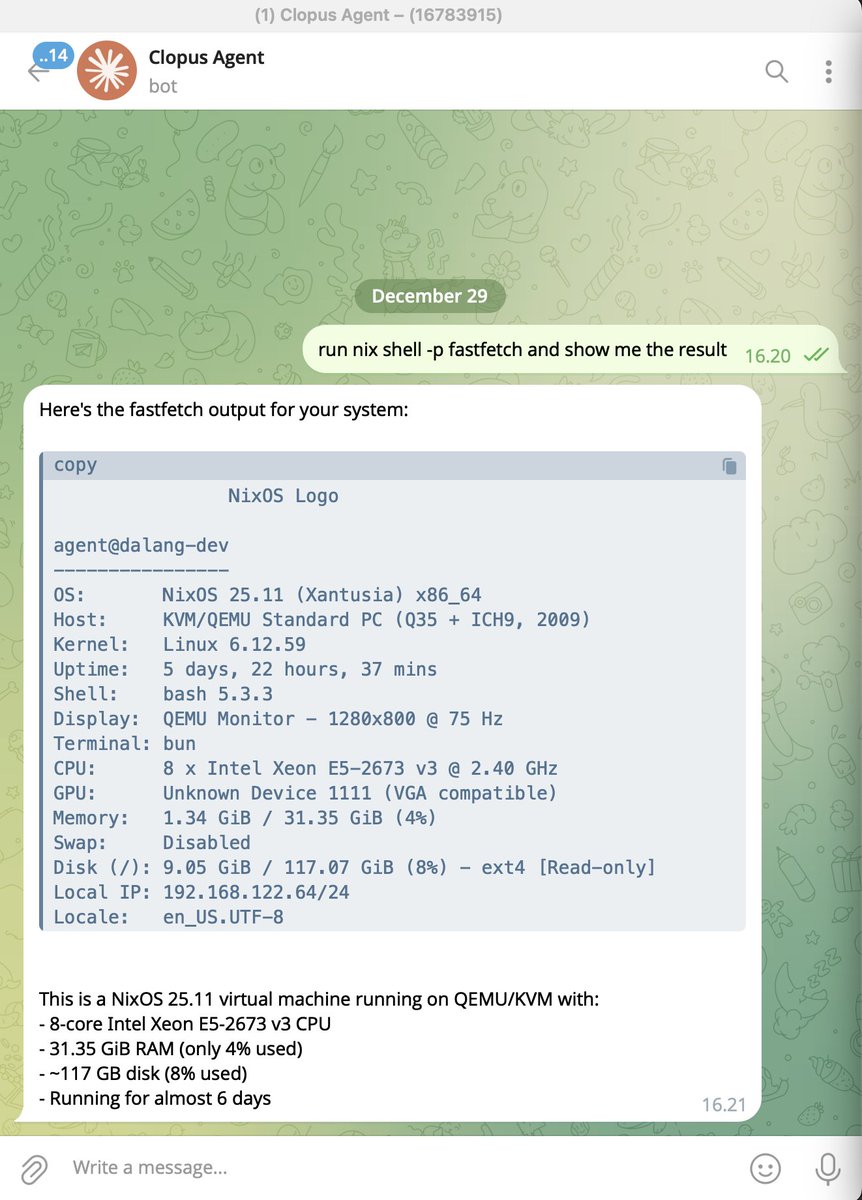 dogfiles@0xrsydn
dogfiles@0xrsydn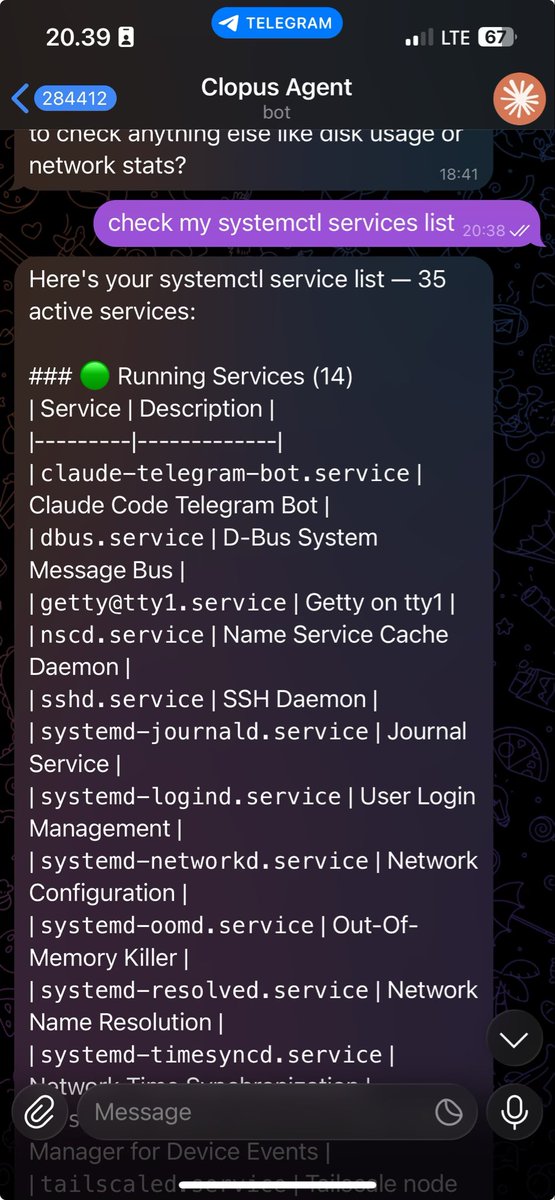
The agent doesn’t need your monitor, keyboard, physical presence, such as your laptop to be open as we can control it remotely.
What the agents need:
- a shell
- access to files (ssh, ftp, etc)
- network
- computer, physically or cloud (ram, cpu, storage/ssd)
gpu soonllm api key/claude code subscription
Do work that really matters, our decision making process, giving direction, and reviewing/human judgement time.
The Mental Model Shift
Hence, we can shift our mental model from as an operator perspective to as a supervisor when we are fully-utilizing an LLM to be as our codemonkey.
We don’t need to see the code writing process, Just need to be present for decision making, code review, taste judgement, and act as the human itself in the human-in-the-loop process (even some of method like ralph loop may not need human intervention).
From this perspective, we can derive it as environment design principles for our setup:
- headless first, if we need GUI like opening an IDE, it’s not agent-friendly.
- persistent sessions. We want to keep the agent running as long as possible
especially codex that running in the background for 10 hours alone. Disconnect shouldn’t kill the work. Use tmux, screen, or zellij to keep the session alive. - separation of concerns. The VM where work happens is stateful while our devices are stateless clients as windows into the work.
Recalling our sci-fi perspective, using jarvis of ironman and t-sphere of mr.terrific as our references here, probably in the future we can view it the interaction between the human and machine via natural language voice. There is emerging app that focuses on turning speech into polished writing like WisprFlow as the closest thing I can imagine to make similar jarvis-tony stark interaction level mimicry.
I haven’t tried it but for mac user, there is local model that we can use such as whisper.cpp to plug in openai whisper locally with your mac. Or..
 🎭@deepfates
🎭@deepfatesKnowing When to Take the Wheel
Even though I wrote about delegation, fully-AI feedback loop most of the time here, not everything should be delegated. Knowing when to delegate and take over are very important too.
Delegate when:
- task is well-specified
- verification is cheap or almost fully-automated
- time is the bottleneck
- failure is recoverable
- the task is safe enough to be handled by an LLM
Take over when:
- when we are debugging the agent more than the problem
- context might be too complex to transfer efficiently
- when we could finish the task faster by doing it ourselves
- critical human-needed review task (ex: handling prod database)
- the task requires judgement we can’t specify
Closing Statement
Different than most of previous blogs I’ve written so far, in this writing, I’m emphasizing more on the thinking process and our approach as we, the human to interact and work with an LLM. What I wrote here might be outdated in the future as the technology of this machine god evolves beyond our current understanding.
We’ve heard that “AI is going to replace the JOB”, “AI will automate most of our life aspects”, and the other things over years. Despite all of that, what truly matters right now are:
- our decision-making ability, the human judgement
- ability to adapt to new situations (obviously)
- communicate effectively with machines (context engineering??)
- ability to collaborate with other humans
- creativity and artistic taste
ability to act and do the thing lol, ppl call it as “high agency”

I don’t know what’s coming next, I might be very very wrong again like previous blogs but what I can do is adapt like mahoraga’s adapting to all incoming sorcerers’ attacks (sorry for inserting cringe jjk panel joke here)

Footnotes
-
Tea dating advice app confirms hack, says 72K images, including selfies, accessed ↩
-
Code execution with MCP: Building more efficient agents, Anthropic ↩
-
Octoverse: AI leads Python to top language as the number of global developers surges ↩
-
Octoverse: A new developer joins GitHub every second as AI leads TypeScript to #1 ↩